
DYO 공부하는 블로그
프론트엔드 엔지니어가 알아야 할 관계형 데이터베이스 (Supabase 기준) 본문
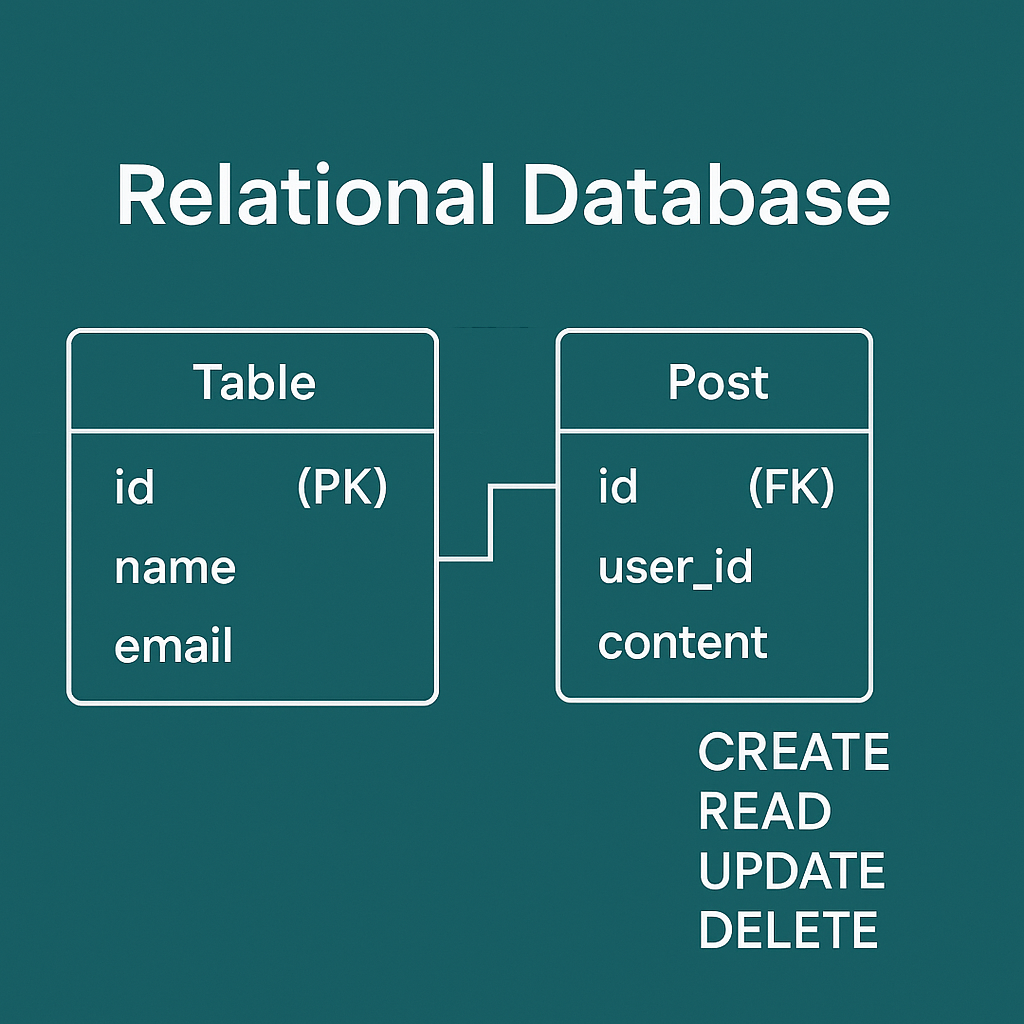
관계형 데이터베이스란?
관계형 데이터베이스는 데이터를 테이블(table) 형태로 저장하고 관리하는 데이터베이스입니다. 여기서 관계형이라는 말은, 데이터를 행(row)과 열(column) 로 구성된 표 형태로 저장하면서, 서로 다른 테이블 간의 관계를 맺을 수 있다는 의미이다.
데이터를 테이블로 관리하는 이유
- 데이터를 구조화해서 중복을 최소화함
- 필요한 데이터만 빠르게 조회 가능 (
인덱스,조건 검색등) - 데이터
일관성,무결성유지 → 실수와 오류를 방지함
데이터베이스와 테이블 분리
- 데이터베이스(DB): 여러 테이블과 객체들의 집합 (프로젝트 전체 데이터)
- 테이블: DB안의 하나의 표 (users, posts, comments) 등
- 테이블은 주제별, 기능별로 나누어서 관리하고 각 테이블이 서로 연결될 수 있음(FK)
테이블의 키
각 테이블에는 키(Key) 를 이용해 다른 행(row)과 구분되는 고유한 값(Unique)으로 열을 구분하거나, 외부의 다른 테이블과 연결된 데이터를 만들 수 있다.
키에는 기본키(Primary Key), 외부키(Foreign Key), 슈퍼키(Super Key), 후보키(Candinate Key) 등의 종류가 있지만, 프론트엔드에서는 기본인 기본키(PK)와 외부키(FK) 만 알아도 충분합니다.
- 기본키(Primary Key) : 테이블의 각 튜플(행)을 고유하게 식별할 수 있는 속성(열)중에 선택된 것 (일반적으로 ID를 많이 사용)
- 외부키(Foreign Key) : 다른 테이블의
기본키(PK)또는고유한 속성을 참조하기 위해 사용하는 키
정규화
정규화 는 데이터의 **중복을 줄이고 데이터 무결성(결점이 없는 특성)**을 높이기 위해 테이블을 구조화하는 것이다.
정규화의 목표
데이터의 일관성을 유지하고 저장 공간 낭비를 최소화한다. 갱신 삽입, 삭제 이상과 같은 오류를 방지하는 것이 목표이다.
정규화 방법들
1NF :
모든 속성은 한 컬럼에 여러 값을 가지면 안 된다.
수정 전: 한 키에 여러 값이 들어감
| 주문번호 | 제품 |
| 101 | 키보드, 마우스 |
수정 후: 한 키에 한개의 값으로 수정
| 주문번호 | 제품 |
| 101 | 키보드 |
| 101 | 마우스 |
2NF :
1NF를 만족하며 기본키가 복합키(여러 컬럼으로 이루어진 키)일 경우 기본키의 일부에만 종속된 속성이 있으면 안 된다.
수정 전 :
기본키는 (학번+과목코드)이지만 과목코드는 강의하는 교수의 교수명에 종속됨.
| 학번(PK) | 과목코드(PK) | 교수명 |
| 1 | CS101 | 김교수 |
| 1 | MA101 | 이교수 |
수정 후 :
(학번, 과목코드) 기본키로 종속되었던 교수명을 과목 테이블로 분리
수강 테이블
| 학번 | 과목코드 |
| 1 | CS101 |
| 1 | MA101 |
과목 테이블
| 과목코드 | 교수명 |
| CS101 | 김교수 |
| MA101 | 이교수 |
3NF :
2NF를 만족하며 **이행적 함수(기본키가 아닌 컬럼이 다른 컬럼을 결정)**가 없어야 함.
수정 전 :
학번이 학과코드를 결정 → 학과코드가 학과명을 결정 과정으로 결정됨
| 학번(PK) | 학과코드 | 학과명 |
| 1 | CS | 컴퓨터 |
| 2 | MA | 수학 |
수정 후:
이중으로 결정하는 이행적 함수를 테이블을 분리해 제거
학과 테이블
| 학과코드 | 학과명 |
| CS | 컴퓨터 |
| MA | 수학 |
학생 테이블
| 학번 | 학과코드 |
| 1 | CS |
| 2 | MA |
이 외에도 BCNF는 자주 사용하지만 다루기엔 조금 복잡하고, 4NF, 5NF등은 매우 복잡하고 자주 사용하지 않으므로 프론트엔드 지식으로는 1, 2, 3NF 정도만 알고 있어도 충분할 것 같습니다.
SQL 기본 문법
자주 사용하는 용어인 CRUD(Create, Read, Update, Delete) 같은 경우는 근본적으로 SQL에서 온 용어입니다. 프로젝트에서 이용할 supabase의 경우에는 명령들이 SQL을 작성하는 구조와 유사합니다.
Create
INSERT INTO posts (title, content) VALUES ('고민 제목', '고민 내용');
posts테이블의 title, content 컬럼에 ‘고민 제목’, ‘고민 내용’을 삽입합니다.
- Supabase에서 같은 동작
const { data, error } = await supabase
.from('posts')
.insert([{ title: '고민 제목', content: '고민 내용' }]);
Read
SELECT * FROM posts WHERE id = 1;
posts 테이블에서 id가 1인 값을 테이블 전체에서 조회합니다
- Supabase에서 같은 동작
const { data, error } = await supabase
.from('posts')
.select('*')
.eq('id', 1);
Update
UPDATE posts SET content = '수정된 내용' WHERE id = 1;
id가 1인 튜플(열)에 content를 ‘수정된 내용’으로 수정합니다.
- Supabase에서 같은 동작
const { data, error } = await supabase
.from('posts')
.update({ content: '수정된 내용' })
.eq('id', 1);
Delete
DELETE FROM posts WHERE id = 1;
posts 테이블에서 id가 1인 튜플(열)을 제거합니다.
- Supabase에서 같은 동작
const { data, error } = await supabase
.from('posts')
.delete()
.eq('id', 1);
추가로 Upsert는 뭔가요?
Insert동작을 하는 동시에, 만약에 기본키 가 동일하게 존재하는 튜플(열)이 있을 경우 삽입한 내용을 삽입을 요청한 내용으로 교체합니다. Supabase는 Postgres 기반이라 지원합니다.
const { data, error } = await supabase
.from('posts')
.upsert({ id: 1, title: '고민 제목', content: '업서트 내용' });
ERD(Entity-Relationship Diagram)
데이터 구조를 한눈에 파악하기 위한 다이어그램. 데이터베이스에 어떤 데이터가 있고 어떤 관계가 있는지 시각적으로 표현한다.
- 개체(Entity)
데이터로 저장할 대상(테이블) 예를 들면 users(유저 테이블), orders(주문) 등. 사각형으로 표현됩니다. - 속성(Attribute)
개체가 가지는 세부 정보(컬럼) 예를 들면 사용자 이름, 이메일, 나이 등과 같은 세부 정보. 타원으로 표시됩니다. - 관계(Relationship)
개체간의 연결/연관성 예를 들면 “사용자는 주문을 한다.”, “게시글은 사용자가 작성한다” 등과 같은 행위를 표현합니다. 마름모 형태로 표현됩니다.

관계의 화살표는 이렇게 표현됩니다.
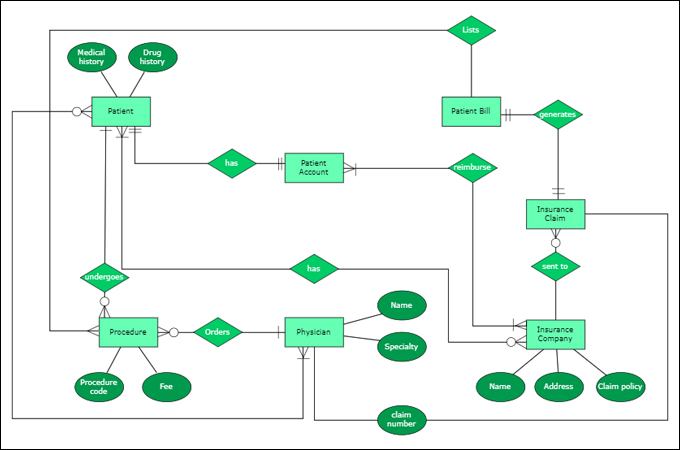
고전적인 ERD 형태는 이런 식으로 표현됩니다.
근데 이건 조금 고전적인 형태고, 현대의 ERD의 요소들은 똑같게 정의하지만 좀 더 간략화한 형태가 되었습니다. Supabase의 자동으로 생성해주는 ERD도 간략화된 형태
- 개체(Entity): 여전히 사각형
- 속성(Attribute): 사각형 내부에 컬럼 형태로 직접 표시
- 관계(Relationship): 마름모 제거, 대신 선 + 다리 모양(crow’s foot)으로 관계 차수(카디널리티) 표시

현대적인 ERD의 예시는 이렇게 표현됩니다.